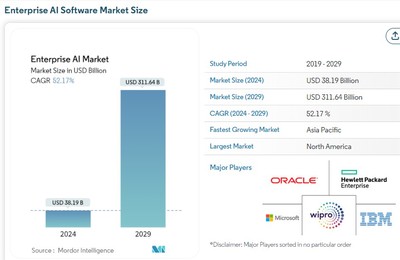
在當今大數(shù)據(jù)與人工智能技術(shù)蓬勃發(fā)展的時代,一系列基礎(chǔ)且強大的算法構(gòu)成了智能系統(tǒng)的核心骨架。其中,k近鄰(k-Nearest Neighbors, k-NN)算法以其直觀、非參數(shù)的特性,不僅在分類任務(wù)中廣為人知,其回歸模型變體——k近鄰回歸(k-NN Regression)——同樣在預(yù)測分析領(lǐng)域扮演著重要角色。本文將探討k近鄰回歸模型的原理、其在大數(shù)據(jù)環(huán)境下的挑戰(zhàn)與優(yōu)化,并闡述其在人工智能基礎(chǔ)軟件開發(fā)中的實踐價值。
一、k近鄰回歸模型:原理與核心思想
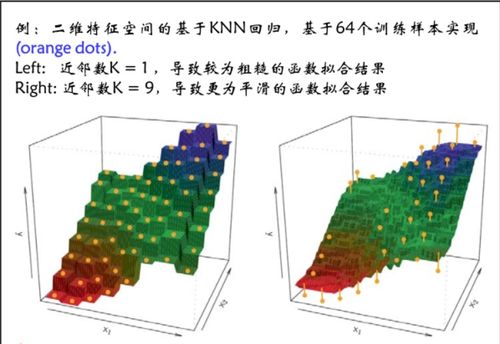
k近鄰回歸是一種基于實例的學習方法,它不試圖構(gòu)建一個顯式的全局模型,而是“記住”所有的訓(xùn)練數(shù)據(jù)。當需要對一個新樣本進行預(yù)測時,算法會在訓(xùn)練集中尋找與該樣本最相似的k個鄰居(通常使用歐氏距離、曼哈頓距離等度量),然后通過對這k個鄰居的目標變量值(通常是連續(xù)值)取平均值(或加權(quán)平均)來預(yù)測新樣本的值。
其核心公式可簡化為:
> ? = (1/k) * Σ y_i (對于簡單平均)
其中,? 是預(yù)測值,y_i 是第i個鄰居的目標值。這種“局部平均”的思想使得k近鄰回歸對數(shù)據(jù)局部結(jié)構(gòu)有很好的擬合能力,尤其適合那些輸入變量與輸出變量之間關(guān)系復(fù)雜、非線性的場景。
二、大數(shù)據(jù)背景下的挑戰(zhàn)與演進
在傳統(tǒng)小數(shù)據(jù)集上,k近鄰回歸簡單有效。面對大數(shù)據(jù)環(huán)境,其面臨顯著挑戰(zhàn):
- 計算復(fù)雜度高:預(yù)測時需要計算新樣本與所有訓(xùn)練樣本的距離,時間復(fù)雜度為O(n),對于海量數(shù)據(jù)(n極大)實時性差。
- 存儲成本大:需要存儲全部訓(xùn)練數(shù)據(jù),內(nèi)存消耗高。
- 維度災(zāi)難:在高維特征空間中,距離度量可能失效,所有點之間的距離變得相似,導(dǎo)致模型性能下降。
為應(yīng)對這些挑戰(zhàn),業(yè)界發(fā)展出多種優(yōu)化策略,這些也正是人工智能基礎(chǔ)軟件開發(fā)需要集成的關(guān)鍵能力:
- 近似最近鄰搜索(ANN)算法:如KD-Tree、Ball Tree、局部敏感哈希(LSH)等,通過構(gòu)建索引結(jié)構(gòu),以犧牲少量精度為代價,大幅提升近鄰搜索速度。
- 降維技術(shù):在主成分分析(PCA)、t-SNE等技術(shù)的預(yù)處理下,減少特征維度,緩解維度災(zāi)難。
- 分布式計算框架集成:利用Spark MLlib、Flink ML等大數(shù)據(jù)計算框架,將數(shù)據(jù)和距離計算并行化,實現(xiàn)可擴展的k近鄰處理。
三、在人工智能基礎(chǔ)軟件開發(fā)中的實踐價值
k近鄰回歸模型作為一種基礎(chǔ)算法,其實現(xiàn)與優(yōu)化是衡量一個AI軟件開發(fā)框架或庫是否成熟、高效的標準之一。它在基礎(chǔ)軟件開發(fā)中的應(yīng)用價值體現(xiàn)在:
- 構(gòu)建標準化機器學習庫:成熟的AI開發(fā)框架(如Scikit-learn、TensorFlow、PyTorch等)均提供高效、穩(wěn)定的k近鄰回歸實現(xiàn),支持多種距離度量、加權(quán)方案和搜索算法,為上層應(yīng)用提供可靠的“積木”。
- 服務(wù)于更復(fù)雜模型的組件:在集成學習、半監(jiān)督學習或某些深度學習模型的預(yù)處理/后處理階段,k近鄰回歸可以作為有效的插補缺失值、平滑輸出或生成偽標簽的基礎(chǔ)工具。
- 原型開發(fā)與可解釋性:由于其原理直觀,k近鄰回歸常被用于快速原型驗證。其預(yù)測結(jié)果可以通過展示“鄰居”來進行解釋,這符合當前對AI可解釋性的迫切需求,有助于開發(fā)具有透明度的AI系統(tǒng)。
- 教育與實踐的橋梁:在AI教學和入門級開發(fā)工具中,實現(xiàn)一個k近鄰回歸模型是理解機器學習基本概念(如距離、超參數(shù)k、過擬合/欠擬合)的絕佳實踐項目,有助于培養(yǎng)開發(fā)者的算法思維。
四、開發(fā)實踐要點
在進行相關(guān)軟件開發(fā)時,開發(fā)者需重點關(guān)注:
- 算法接口設(shè)計:提供清晰的fit/predict接口,支持樣本權(quán)重、多輸出回歸等擴展功能。
- 性能優(yōu)化:針對大數(shù)據(jù)場景,默認集成ANN算法或提供便捷的插件接口。
- 與數(shù)據(jù)處理流水線無縫集成:能夠與特征縮放、編碼、管道(Pipeline)等組件協(xié)同工作。
- 自動化與自動化機器學習(AutoML):提供超參數(shù)k和距離度量的自動搜索與優(yōu)化功能,降低使用門檻。
###
k近鄰回歸模型,作為從大數(shù)據(jù)中挖掘價值的經(jīng)典工具之一,其生命力在于簡單性與擴展性的結(jié)合。在人工智能基礎(chǔ)軟件開發(fā)中,深入理解和高效實現(xiàn)此類基礎(chǔ)模型,不僅是構(gòu)建強大AI系統(tǒng)的技術(shù)基石,也是推動AI技術(shù)民主化、賦能各行各業(yè)智能化轉(zhuǎn)型的關(guān)鍵一步。隨著硬件算力的提升和算法的持續(xù)創(chuàng)新,k近鄰回歸及其思想必將在邊緣計算、實時預(yù)測等新興場景中煥發(fā)新的光彩。